How to Sort Read Handwritten Number Python
How to classify handwritten digits in python
Without the assistance of any machine learning libraries
![]()
If you have read the previous articles in this serial (links at bottom of page), you should have built a DNN class completely from base principles. Allow'south see if we tin can use this class to create a neural network that'due south able to read handwritten digits.
This is a classic example of something that is easy for united states humans to do, but it is incredibly hard to write a program that accomplishes the same task. In the case of us humans classifying pictures, let's think almost what is happening. For a human looking at an epitome, the encephalon is receiving input in the form of photons and classifying the image based on this input.
Based on this nosotros tin say that in that location must be some relationship betwixt the photons hit our middle and the content of the picture. Obviously, correct? Of form, what the picture looks similar has something to do with what the film is of. Just, modeling this mathematically requires this suggestion;
There exists some mathematical function that tin can tell us what is in the picture, based on the input (photons) we receive from the flick.
Nosotros will be finding this incredibly complicated function easily, using a neural network.
Getting and cleaning our information
In the spirit of advancing AI, the Modified National Institute of Standards and Technology (MNIST) has put together 10'southward of thousands of pictures of handwritten digits, each with a label. This data can exist downloaded here. Below is an case of i of these digits.

Now, in the instance of u.s. humans, we receive input as photons entering our optics. Similarly (sort of), to a computer this picture is just a matrix of pixel values. These pixel values range from 0 to 255 (since the image is black and white), as shown below:
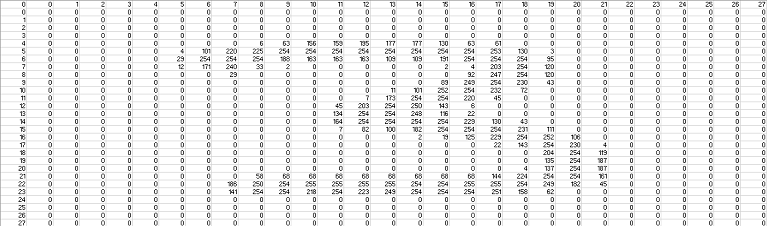
These pictures are 28X28, with 784-pixel values. Our goal is to map these 784-pixel values to the number that is written. So, let'south get started. Let'southward first look at the data. You should have downloaded a cypher binder from the Kaggle link I provided to a higher place. After you unzip the folder yous will encounter a mnist_test and mnist_train CSV. For right now we will only exist focused on the mnist_train CSV. Below I use pandas to open up the file, and so show the contents of the file.
import pandas as pd
import numpy every bit np
import matplotlib.pyplot as plt data = pd.read_csv('mnist_train.csv')
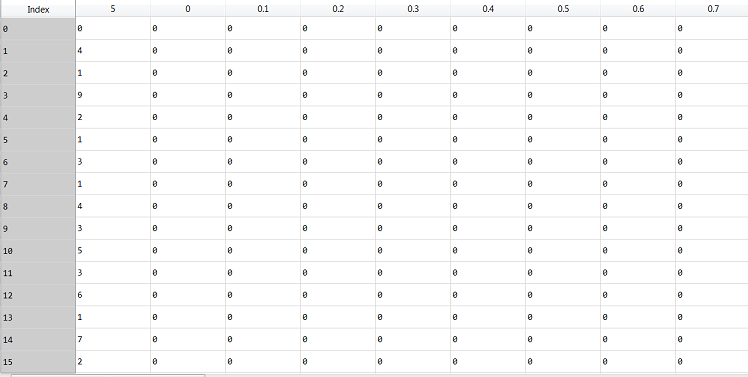
As yous can see, the first column of this data is the labels (the number that the image represents), and the residue are the pixel values for the image (totaling 785 columns). Each row is an individual epitome. Using pandas iloc office we tin separate the inputs from the labels. Also, we ensure that the input is normalized between 0 and i.
labels = np.array(information.iloc[:,0])
x_train = np.array(data.iloc[:,ane:])/255
# We dissever past 255 then that all inputs are between 0 and 1 Our side by side stride may seem odd, only it is essential. Correct now each characterization is just one number or one dimensional. This means the neural network must output the correct number between 0 and 9. Nosotros can make the nomenclature task easier for our neural network by increasing the dimensions of the output to 10 dimensions, ane for each number. For instance, we will alter the label '0' so that it is '[ane,0,0,0,0,0,0,0,0,0], '1' = '[0,1,0,0,0,0,0,0,0,0] and so on. This is chosen 'i-hot-encoding', and I do this for our labels beneath.
encoded_labels = []
for i in range(len(labels)):
naked = [0,0,0,0,0,0,0,0,0,0]
naked[labels[i]] = i
encoded_labels.append(naked) Now nosotros can use matplotlib to check out what these images actually look similar.
# Take a look at what the images wait like
random_index = np.random.randint(0,40000)
img = x_train[random_index].reshape(28,28)
plt.imshow(img, cmap = "gray") As y'all can see, our neural network actually has its piece of work cut out for it with some of these pictures…
Creating our Neural Network and grooming
Nosotros will be using the DNN class we created in the article prior to this one (found here). Each image has 784 inputs and 10 outputs, I volition cull 1 hidden layer with 1250 neurons. Therefore, our layers would be [784,1250,10]. Inside a for loop, nosotros simply generate a random index, then run the train function on the data and label that corresponds to this index. I also impress some useful information every thousand steps, meet below:
model = DNN([784,1250,10]) from collections import deque
mistake = deque(maxlen = 1000)
"""A deque is just a list that stays at 1000 units long (last item gets deleted when a new item gets added when at length = chiliad)""" for n in range(30000):
index = np.random.randint(0,59998)
mistake.append(model.railroad train(x_train[alphabetize], encoded_labels[index]))
if n%1000 == 0:
print("\nStep: ",n)
print("Average Error: ", sum(error)/grand)
plt.imshow(x_train[index].reshape(28,28), cmap = "gray")
plt.show()
print("Prediction: ", np.argmax(model.predict(x_train[index])))
Results and testing
After merely 5 minutes on my computer, the NN is correctly identifying well-nigh of the digits. After 10 minutes the neural network seems as if it has fully trained, reaching an average mistake of effectually .2. It is important non to over-railroad train the model, this causes the NN to just memorize images which would make information technology actually bad at predicting things it has never seen.
Let'due south use that mnist_test.csv file nosotros downloaded to see how well our neural network performs on data it has never seen before. Beneath I call the predict part on each motion-picture show in the mnist_test file, and then check if the prediction was correct. I and so calculate the percent that this NN predicted correctly.
test_data = pd.read_csv('mnist_test.csv')
test_labels = np.assortment(test_data.iloc[:,0])
x_test = np.array(test_data.iloc[:,i:])/255 correct = 0 for i in range(len(test_data)):
prediction = np.argmax(model.predict(x_test[i]))
if prediction == test_labels[i]:
correct +=i percent_correct = right/len(test_data) * 100
print(percent_correct,'%')
Below is the final code for this project:
I cease upwardly getting a 93.5%. Experience complimentary to try to train longer, increase the number of layers and/or neurons, alter the activation function or loss function, and modify the learning charge per unit to see if this tin be improved. Although 93.5% is very heady, we can actually exercise much improve. We tin make the neural network able to place unique features within the picture to aid it identify the image. This is the thought behind convolutional neural networks, which I will explain in detail in a future article.
Thank you for reading! If this post helped you in some style or yous have a annotate or question then please leave a response beneath and let me know! Also, if you lot noticed I made a fault somewhere, or I could've explained something more clearly then I would appreciate it if you lot'd let me know through a response.
Source: https://towardsdatascience.com/how-to-classify-handwritten-digits-in-python-7706b1ab93a3
0 Response to "How to Sort Read Handwritten Number Python"
Post a Comment